Intro to Clusters and High Performance Computing
This section provides a high-level overview of high performance computing (HPC) and clusters. Getting started with Linux and HPC clusters can be a hurdle for new users, although our experience is that it becomes routine after a few times. We can’t provide comprehensive training on all aspects of cluster use in this section, but we can orient you so that you know some of the lingo and can intelligently progress with HPC resources.
Anatomy of a Cluster
A typical HPC cluster (Figure: Cluster Components) consists of several interconnected components. Users usually connect to the cluster using a Linux front-end tool such as MobaXterm, PuTTY, or similar, logging into a special machine called the head node.
The head node is not intended for computation—at a major facility, this node is a shared resource, and running jobs on it is discouraged. Instead, the head node connects you to:
Shared scratch storage
A job queueing system (e.g., Slurm, Torque, PBS)
You will upload your input data to a designated scratch location. This is typically not your home directory on the head node, so be sure to check with your system administrator or facility documentation.
Figure: Cluster Components
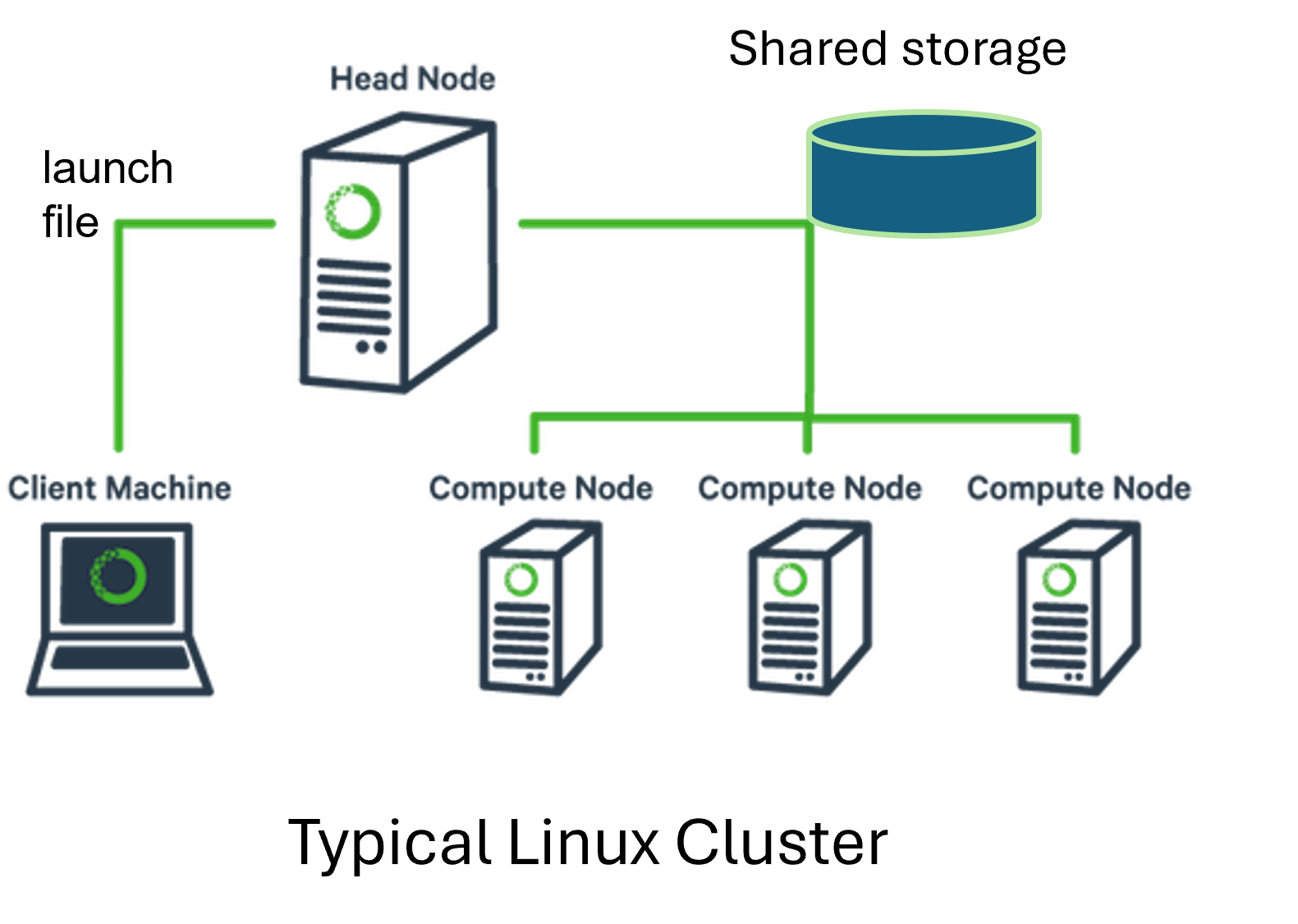
Fig. 11 Figure: Schematic layout of a typical HPC cluster showing login (head) node, compute nodes, shared storage, and interconnects.
Compilation
As with most Linux programs, when migrating to a new cluser one needs to compile the code for the system, taking care of dependencies such as cmake, compilers, MPI and NetCDF. These are common components and your vendor should be able to help (we can help interpret a good faith effort). Some users are used to this compilation process, which is also required if you want to modify the model.
An alternative is to use Intro to Batch Cloud Cluster, which may provide enough control to allow you to use versions we have prepackaged.
Job Submission
The job queueing system manages run submissions and dispatches them according to a scheduling policy, often based on priority, available resources, and fair use policies. While queue systems differ slightly, they all support core operations such as:
Submitting a job
Listing jobs in the queue
Canceling a job
Once your inputs are organized, you can submit a job in Slurm using:
$ sbatch launch.slurm
Here, sbatch is the Slurm submission command, and launch.slurm is your job launch file.
This file typically specifies:
Your user information
The job name
Number of nodes and cores to request
The command to run your application
Job submission syntax and behavior (e.g., handling of environment variables, working directories, and node allocation) may differ slightly across systems. We are happy to provide example files upon request.
The job file usually ends by calling a shell script (e.g., run_schism.sh), which in turn
invokes the SCHISM model. The script may load necessary modules or libraries depending on
your build of SCHISM (e.g., whether it includes age tracking, sediment transport, etc.).
Compute Nodes and Message Passing
The actual computations are carried out on compute nodes. A node is a unit of compute resources that includes:
RAM
Disk space
One or more processors, which in turn include multiple cores
In SCHISM, the spatial domain (e.g., the San Francisco Bay-Delta) is split into subdomains for computation across multiple cores. These nodes are connected via high-speed interconnects such as InfiniBand.
Because SCHISM uses domain decomposition, the model must exchange data between cores at each time step. This communication occurs along shared subdomain boundaries and is handled via MPI (Message Passing Interface)—a standardized and efficient protocol for data exchange in parallel programs.
MPI performance is heavily influenced by both hardware quality (e.g., latency and bandwidth of the interconnect) and the quality of the MPI library implementation.
Important Notes:
There is no “main core” or centralized controller in a well-designed MPI program.
The head node does not participate in computation or MPI communication—it only handles job submission and user interaction.
Input/Output and Scribes
SCHISM uses a small number of dedicated scribe cores for writing output to disk. Typically:
One scribe handles all 2D NetCDF output files.
One additional scribe is assigned for every 3D NetCDF output file.
These scribes are necessary to avoid contention and ensure efficient parallel I/O.
Example Slurm Launch File
Here is a real-world example of a Slurm job submission file for running SCHISM:
#!/bin/bash
#SBATCH --job-name=msstps # Job name
#SBATCH --partition=work # Partition name to submit the job
#SBATCH --mail-type=END,FAIL # Mail events (NONE, BEGIN, END, FAIL, ALL)
#SBATCH --mail-user=eli@water.ca.gov # Where to send mail
#SBATCH --ntasks=192 # Number of MPI ranks (or cores)
#SBATCH --nodes=6 # Number of nodes
#SBATCH --ntasks-per-node=32 # Tasks per node
#SBATCH --output=slurm_log_%j.log # Standard output and error log
module load intel/2024.0
module load hmpt/2.29
mpirun bash schism_hmpt.sh
Example Shell Script to Run SCHISM
The shell script below is used to configure the environment and invoke the SCHISM binary:
#!/bin/bash
module purge
module load intel/2024.0 hmpt/2.29 hdf5/1.14.3 netcdf-c/4.9.2 netcdf-fortran/4.6.1 schism/5.11.1
ulimit -s unlimited
NSCRIBES=7 # This is the number of scribes for the example
SCHISM_BIN=pschism_PREC_EVAP_GOTM_TVD-VL
$SCHISM_BIN $NSCRIBES
Intro to Batch Cloud Cluster
Figure: Cluster Components shows how Azure Batch processing differs. In this mode of processing, inputs are uploaded to a long-term Binary Large OBject (BLOB) storage location.
Batch jobs are then launched through Azure Batch, and the assigned computional pool pulls down the inputs, acts as a cluster to run the model, and pushes back outputs as they are generated. This method tends to be very economical and it allows prepackaging of versions. The downside is that it is not very agile and feels a it detached. For instance, we tend to develop our runs on in-house clusters and then once the based case is settled we run the larger set of scenarios on Azure Batch.
Figure: Azure Batch Cluster Components
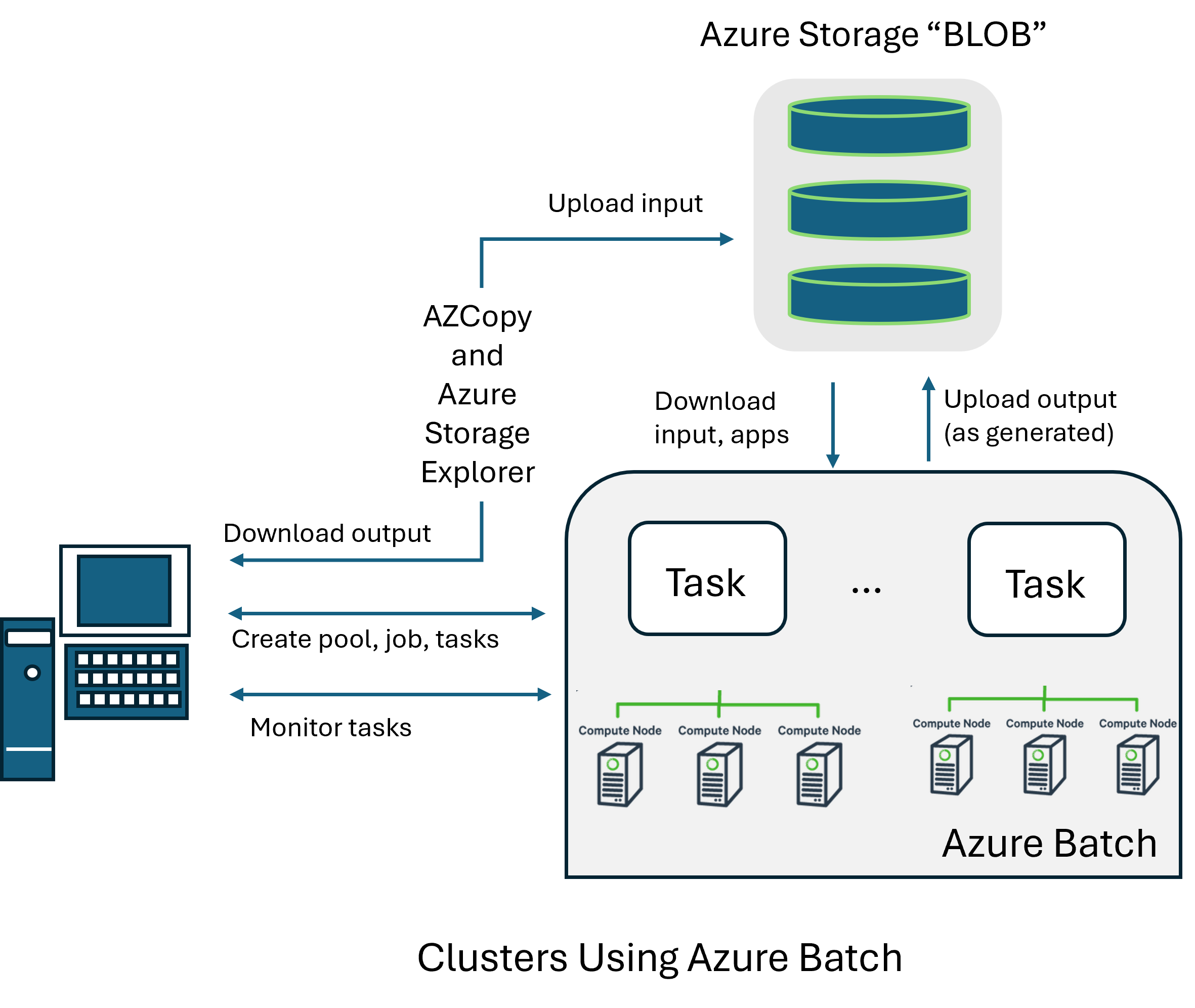
Fig. 12 Figure: Schematic layout of a typical HPC cluster showing login (head) node, compute nodes, shared storage, and interconnects.