Run Initialization and Restart (Hotstart)
When do you need an initial condition or hotstart?
You should use a hotstart or initialization for every study if you include salinity transport or other tracers. The need for this may be unfamiliar if you are coming from a lower dimensional model or less resolved 3D model. There are two reasons:
the domain is really big, so moving the salt in correctly via a cold start would take many months and
if salinity is only coming in from the ocean a sharp baroclinic barrier shock will develop with possibly odd behavior.
We mostly do barotropic runs (no salinity or transport) as a warmup to generate our ocean boundary. For that a cold start from very basic (zero velocity, flat water elevation) is fine.
What is the difference between a cold and hot start?
A cold start means values are initialized from very simple and well behaved values. Typically velocity is zero and the water surface is flat. This avoids “mini-tsunamis” that develop if we try to get too clever with the initial water surface profile. Cold starts are invoked using ihot=0 in the control file param.nml. You also need plausible values for initialization. If you our using our schism templates and requires some initial conditions be provided in the form of text *.ic files which are like *.gr3 files with values at each node, but don’t have mesh topology in the file (and param.nml.tropic control file suggestions for a barotropic run) then a cold start is assumed and the text initialization file elev.ic (and any other *.ic file) will be built.
A hotstart means initializing a model with non-trivial values. There are two main cases:
- ihot=1 (initial condition)
- Start of run. In this case the hotstart file is compiled by the user using interpolated data. Often for this case the assumptions for elev and velocity are simple and the details are supplied
only for tracers like temperature/salinity
- ihot=2: (restart)
- Restart of run. This is used in case you are transitioning to new conditions (say, at the
branching point where study alternatives diverge), invoking a new set of modules or backing up and restarting a failed run. In this case the hotstart file is generated by checkpoint hotstarts written out at regular intervals (often we choose one per five days). These are fragmented files, one per-processor, and need to be combined using the combine_hotstart utility. This utility and a utility hotstart_inventory are described below.
Choosing a good start time
By convention, our group chooses start times that coincide with USGS cruises. . Those are the days when you will have the best access to details on salinity and temperature in the Bay. Note that many cruises are partial, involving only say 20 stops and covering perhaps only the South Bay. You will want a date with a complete cruise. At the Delta Modeling Section we keep an inventory of these.
Hotstart files are not trivially exchangeable when the grid changes or if you change modules (for instance, adding AGE midway through). However, if you have a hotstart from another grid or simulation, the schism_hotstart utility does have an option for initializing by interpolating from the prior hotstart onto the current mesh.
For model initialization, you will also need to consider your strategy for nudging. Nudging means the pushing of the model towards data, which can tremendously speed up the initialization process and make it more accurate. We use nudging at all times at the ocean boundary for salt and temperature, essentially using it as a softer and wider boundary layer. We also sometimes use nudging based on observations in the Delta if we are doing an operational run with observed data and looking at the near term consequences of an action. Under these conditions, one usually wants the model to be spun up fast and accurately. If we are doing longer term planning simulations or if there is branching into alternatives, nudging may not have a role. Also labeling must be exceedingly clear. NEVER REPORT AS GENERAL MODEL ACCURACY STATISTICS ANY RESULTS USING MODELS THAT ARE ACTIVELY NUDGED INSIDE THE GOLDEN GATE.
The two pictures below show the common initialization sequences, as well as the extension into the main study period.

Fig. 8 Simple initialization without nudging using Delta observations data. * = Prefer USGS cruise date.
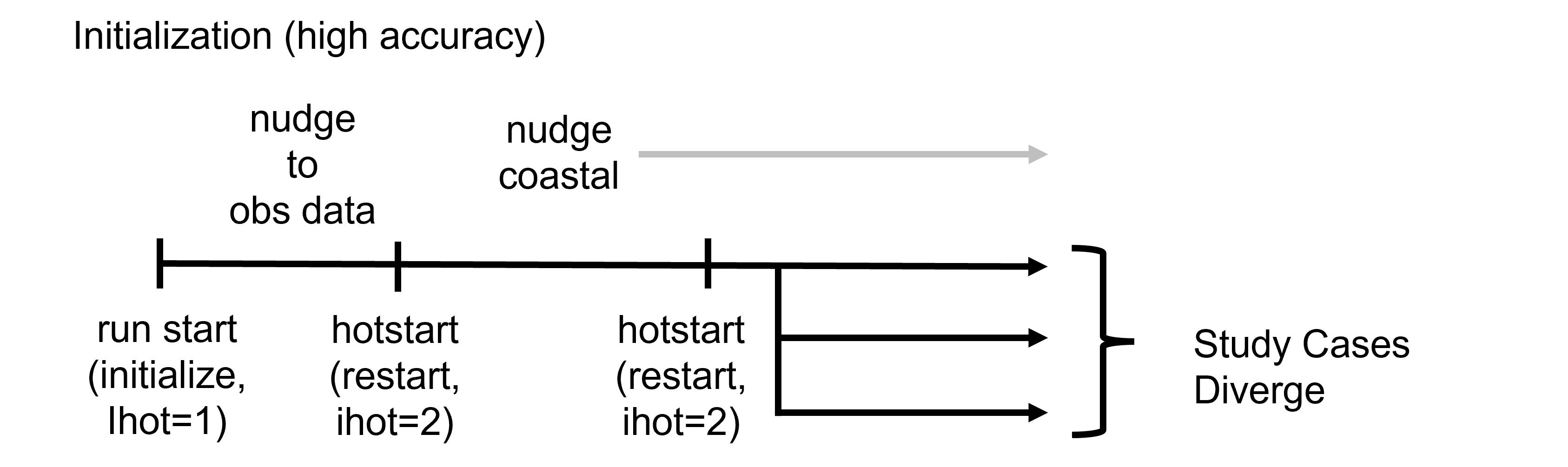
Fig. 9 Simple initialization with nudging using Delta data to spin up the model fast and accurately, before halting and restarting without nudging for the main study.
Creating a Hotstart for Hydro/Salt/Temp with schism_hotstart
Acquiring the data
It is hard to generalize all the different systems used by modeling groups to gather up observed data. The short answer is that for a hotstart you will need a USGS cruise file (downloading the whole year is fine, that is the way their interface looks at the time of writing).
If you are using in-Delta observations you will also need QA/QC’d data at least for the instant of the hotstart. Within the Delta Modeling Section, the script that does gathers these is BayDeltaSCHISM/bdschism/bdschism/hotstart_nudging_data.py. That script assumes a data repository full of observed data from multiple agencies that is not yet disseminated. If you need help, please contact us.
Combining Hotstarts and Managing Restart Files
In modern SCHISM workflows, combining hotstarts is a routine operation and no longer something that should be done manually. The process has three steps:
Identify which hotstart (time step / date) you want.
Combine the per-processor hotstart files into one file.
Move it out of
outputs/and give it a meaningful name.
Historically, this was done by hand using the native SCHISM utility
combine_hotstart7 (the trailing number varies by SCHISM version).
A typical manual workflow looked like the following:
cd outputs
combine_hotstart7 -i 24000
mv hotstart_it=24000.nc ../hotstart.20210515.24000.nc
This still works, but it requires you to know which iteration corresponds to which calendar date and where to put the final file. We now automate this process for consistency and to reduce the chance of user error.
Hotstart Inventory Utility (schimpy.hotstart_inventory)
The hotstart_inventory tool reads the hotstart files in your outputs/
directory and constructs a table linking:
iteration (SCHISM time step),
model datetime (based on
run_startanddt),and hotstart file availability.
This means you no longer need to calculate dates by hand. For example:
hotstart_inventory --workdir outputs
might print something like:
2014-03-25T00:00:00 iteration 7200
2014-03-25T12:00:00 iteration 10800
2014-03-26T00:00:00 iteration 14400
The same utility is available from Python:
from schimpy.hotstart_inventory import hotstart_inventory
df = hotstart_inventory(workdir="outputs")
print(df)
This returns a pandas DataFrame indexed by datetime with one column,
iteration. This date ↔ iteration mapping is also what powers the new
combine_hotstart workflow described next.
Automated Hotstart Combining (bdschism.combine_hotstart)
The bdschism CLI and library provide a wrapper around the native
combine_hotstart7 program. The wrapper:
finds the correct hotstart in the inventory,
calls the SCHISM combine utility for the right iteration,
renames the result using a consistent convention,
optionally archives it, and
optionally creates
hotstart.ncin the run directory for restart runs.
This avoids the need to enter outputs/ manually or guess iteration numbers.
### File Naming Convention
The wrapper names combined hotstarts as:
hotstart[.PREFIX].YYYYMMDD.ITER.nc
Examples:
hotstart.20240312.14400.nc
hotstart.clinic.20240312.14400.nc
The optional PREFIX is useful when creating multiple hotstarts for different
scenarios (e.g., clinic vs. tropic configurations).
### Typical Use Cases
1. Get the latest hotstart and make it the restart file
combine_hotstart --latest --links --prefix clinic
This creates hotstart.clinic.YYYYMMDD.ITER.nc in the run directory and a
link named hotstart.nc pointing to it (required for ihot=2 restarts).
2. Choose the last hotstart on or before a specific date
combine_hotstart --before 2014-03-26 --prefix retro
Useful for runs aligned with field observations (e.g., USGS cruises).
3. Combine a specific iteration
combine_hotstart --it 14400 --out-dir hotstart_archive --prefix retro
4. Archive every Nth hotstart
combine_hotstart --every 10 --out-dir hotstart_archive
This writes only selected hotstarts (10th, 20th, …) into hotstart_archive/.
### Python API
You may also use the wrapper programmatically:
from bdschism.combine_hotstart import combine_hot
files = combine_hot(
run_dir=".",
outputs_dir="outputs",
prefix="clinic",
latest=True,
links=True,
)
This returns a list of absolute paths to the newly created combined hotstarts.
Why This Matters
Combined and dated hotstart files serve three roles:
They document model readiness at specific points in time.
They allow reruns and branching studies without repeating long spinups.
They provide stable initial conditions when modules are changed or new alternatives are introduced.
The bdschism.combine_hotstart workflow standardizes naming, reduces errors,
and maintains a clean audit trail of how and when hotstarts were created.
combine_hotstart is now the recommended way to prepare restart files for all
production SCHISM runs.
ihot=2 in param.nml continues to be the SCHISM-side “restart mode”, but
the management and naming of hotstart files is handled entirely outside the
model via this utility.